Hi 👋, I'm Muh Mubeen !
Nice to meet you.
Senior Data Solution Architect with 11+ years of experience designing scalable cloud-native data platforms, real-time analytics systems, and AI-ready Lakehouse architectures across AWS, Azure, and GCP. Expertise in Databricks, Snowflake, Spark, Kafka, ETL/ELT pipelines, and data warehousing, with a strong track record of optimizing performance, reducing infrastructure costs, and delivering enterprise-scale data solutions across healthcare, finance, and cloud ecosystems.
Featured
Little more about me!
Skills
A quick snapshot of my toolkit
Experience
Data Solution Architect
Technologies
Highlights
- Architected scalable cloud-native data platforms across AWS, Azure, and GCP using Databricks, Snowflake, and Kafka.
Designed real-time streaming pipelines with Apache Kafka, Flink, and AWS Kinesis, improving operational responsiveness by 35%.
Led enterprise cloud migration initiatives, reducing infrastructure costs by 50% and improving query performance by 60%.
Developed AI/ML-ready Lakehouse architectures using Microsoft Fabric, Delta Lake, and Databricks.
Built and optimized 250+ ETL/ELT workflows using Airflow, Talend, Informatica, and Apache NiFi.
Implemented enterprise-wide data governance, HIPAA/GDPR compliance, and secure access management.
Mentored cross-functional engineering teams and implemented CI/CD automation using Jenkins, Docker, Kubernetes, and Terraform.
Senior Data Engineer
Technologies
Highlights
- Developed cloud-scale ELT pipelines using Apache Spark, Snowflake, and Apache Airflow for enterprise analytics.
Implemented Data Mesh-aligned architectures to improve distributed data ownership and reliability.
Optimized Apache Spark workloads, significantly reducing query execution times and improving scalability.
Automated ingestion and transformation pipelines using Apache NiFi and Airflow across multi-cloud environments.
Supported ML workflows using Databricks and MLflow by delivering feature-ready datasets.
Built CI/CD pipelines with Jenkins and GitLab CI for faster and reliable deployments.
Led cloud data warehouse migrations and enabled real-time reporting solutions
Data Engineer
Technologies
Highlights
- Designed and implemented scalable cloud-based data lakes on Google Cloud Platform (GCP).
Developed automated data quality validation frameworks using Great Expectations, reducing discrepancies by 40%.
Integrated REST APIs, flat files, and cloud databases into centralized analytics platforms.
Standardized enterprise data models and schema designs for improved reporting consistency.
Collaborated on cloud infrastructure automation and CI/CD implementation using Terraform.
Supported healthcare analytics and precision oncology research through scalable data engineering solutions.
Projects

Data Solution Architect
Designed and led the development of a real-time healthcare analytics platform integrating EHR and claims data using Apache Kafka, Apache Flink, and AWS Kinesis.
Enabled predictive insights for population health management and reduced data processing latency by 60%.
Deployed HIPAA-compliant data pipelines with Apache NiFi and Airflow on AWS, enhancing care quality and regulatory compliance.
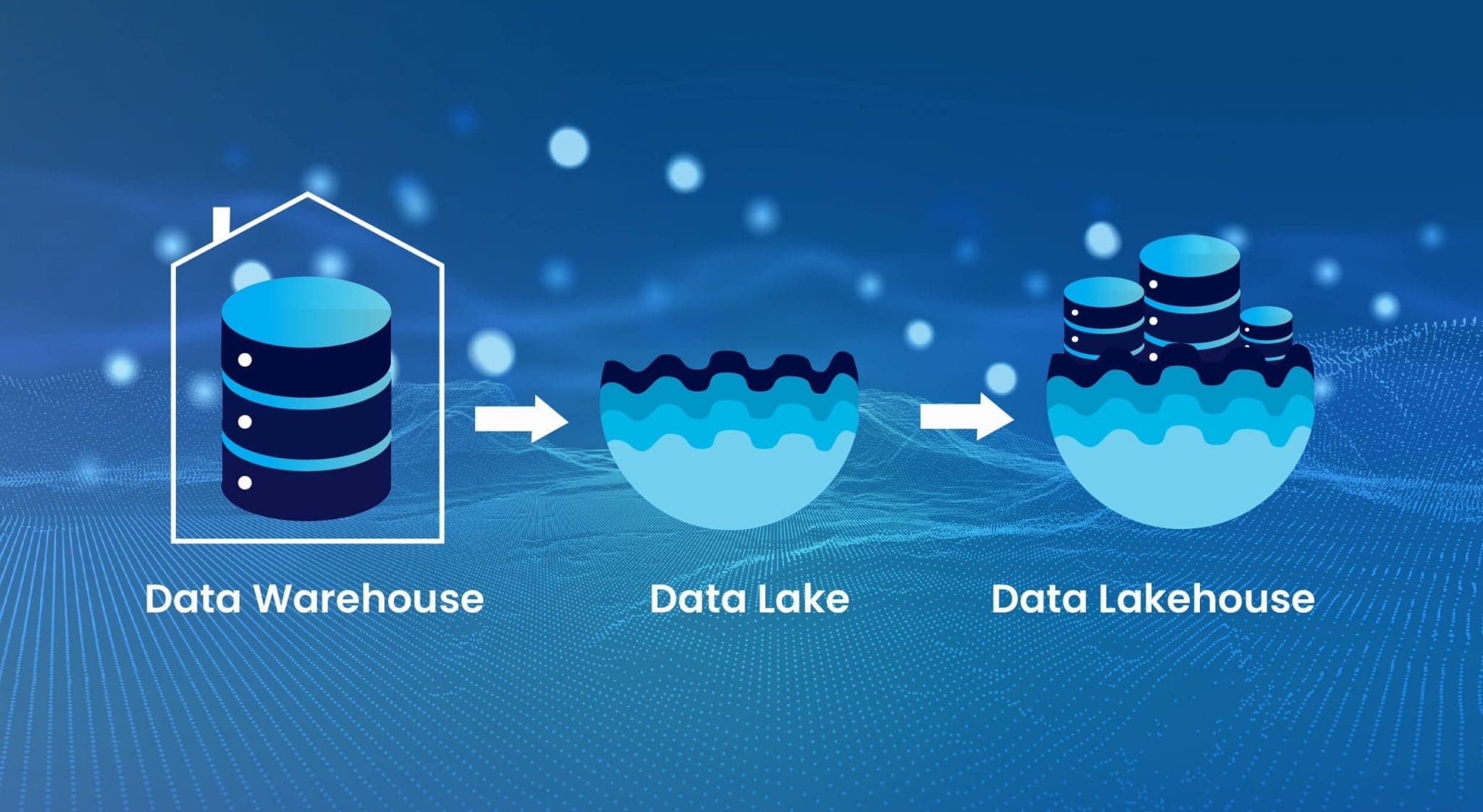
Cloud Data Lakehouse Migration
Led the migration of legacy on-premises data infrastructure to a unified cloud-based lakehouse using Databricks and Delta Lake on Azure.
Streamlined ETL workflows using Apache Spark and Talend, improving data refresh rates by 70%.
Integrated machine learning models with MLflow to forecast energy demands, increasing predictive accuracy by 30%.

Financial Data Pipeline Modernization
Developed scalable ETL pipelines with Apache Beam, Python, and Google Cloud Dataflow, processing over 10 million financial records daily.
Designed a cloud-native data lake on GCP, enabling seamless access to structured and unstructured data for cross-team analytics.
Implemented automated data validation and quality checks using Great Expectations, reducing data inconsistencies by 40%.
ML Feature Store for Fraud Detection
Designed and deployed a centralized ML Feature Store using Databricks, MLflow, and Feast, enabling 3× faster model iterations. Reduced fraud detection false positives by 18% through real-time feature engineering.